Build a HTML parser using struct tags in Golang
As a total beginner to Golang I find struct tags a very interesting idea. With tags, I can separate the data structure from the meta data used by other parties. It’s similar to how HTML and CSS are separated by class names. While doing my side project, I implemented a package to parse HTML content similar to how the native XML parser works. This blog post summarizes the process. I will assume that if you read this you probably have used struct tags before, and have a basic understanding about them.
It all started with a simple idea about an interface to describe how a HTML parser should work without it being tied to the underneath parser logic. The main problem is that each parser implementation provides its own structs and ways to work with HTML. I need a more abstract approach.
Fortunately, HTML parsing at its core is just returning DOM nodes based on a valid CSS selector. HTML parsing packages usually build their own conventions on top of DOM nodes to make traversing through them easier. What I wanted to achieve was an abstract parser that recieves a slice of byte, a struct and returns error if any. Behind the scene, it will fill the struct with appropriate data based on the tags provided. It’s similar to how xml package works, but of course a lot simpler.
Let’s start with an interface
type HTMLParser interface {
Parse(content []byte, structure interface{}) error
}
and how I can use it
type Entry struct {
Title string `html:".title"`
Title string `html:".content"`
ReadTime int `html:".read-time"`
}
type HTMLPage struct {
Date string `html:".articles > .published"`
Entries []Entry `html:".article"`
}
var parser HTMLParser
func main() {
htmlContent, err := GetPage(url) // this returns []bytes
parser = NewParser()
var page HTMLPage
// as a non-native English speaker I have no idea about the differences
// between Unmarshal and Parse so I just go with what I usually use in JS
err = parser.Parse(htmlContent, &page)
}
Similar to the native XML package, I have a struct with some tags to describe how each field should be mapped to a CSS selector. And here is the HTML structure
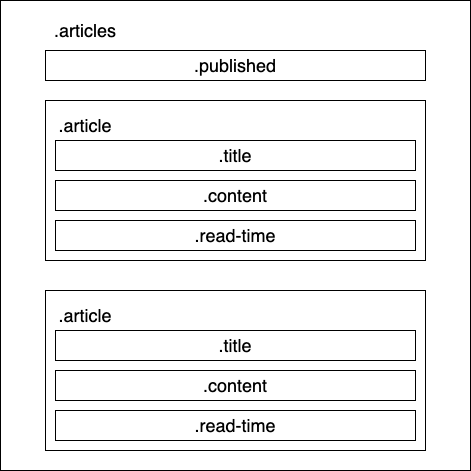
Next, I need to implement the actual logic to unpack the struct tags and do something with them. I’m gonna build the first version using goquery
func NewParser() *GoQueryHTMLParser {
return &GoQueryHTMLParser{}
}
type GoQueryHTMLParser struct {
}
func (p *GoQueryHTMLParser) Parse(content []byte, structure interface{}) error {
r := bytes.NewReader(content)
doc, err := goquery.NewDocumentFromReader(r)
if err != nil {
return err
}
return recursivelyParseDoc(doc.Find("html"), structure)
}
First step is to convert []byte into an io.Reader via bytes.NewReader because goquery only accepts io.Reader (or maybe I don’t know how to make it work with []byte). I decided to go with []byte instead of io.Reader as the parameter because byte is a primitive type and easier to pass around or store somewhere.
The main logic happens inside recursivelyParseDoc which (as the name suggest) recursively goes through the passed struct and find related DOM nodes to extract data. If you are not familiar with goquery, doc.Find("html") returns a Selection. I will mostly work with Selection struct and only do simple query/data structure, otherwise this blog post will become a novel due to complex nature of HTML parsing :(
Alright! Here we go
func recursivelyParseDoc(doc *goquery.Selection, structure interface{}) error {
structType := reflect.TypeOf(structure)
if structType.Kind() != reflect.Ptr {
return fmt.Errorf("must pass a pointer")
}
// ...
}
First thing first, I need to make sure that the passed structure is a pointer, otherwise, I won’t be able to write anything. Next I need to enforce it to be a struct so to prevent people (mostly me) from passing anything weird into the function
func recursivelyParseDoc(doc *goquery.Selection, structure interface{}) error {
// ...
elem := structType.Elem()
if elem.Kind() != reflect.Struct {
return fmt.Errorf("must pass a struct")
}
// ...
}
The Elem() method is an interesting one, from the documentation it says
Elem returns the value that the interface v contains
or that the pointer v points to.
It panics if v's Kind is not Interface or Ptr.
It returns the zero Value if v is nil.
In this case, it returns the type that the pointer points to. Now that I have the type of the struct passed to the function, it’s time to inspect its structure.
const selectorTagName = "html"
func recursivelyParseDoc(doc *goquery.Selection, structure interface{}) error {
// ...
for i := 0; i < elem.NumField(); i++ {
field := elem.Field(i)
if field.Tag == "" {
continue
}
tagValue := field.Tag.Get(selectorTagName)
if tagValue == "" {
continue
}
kind := field.Type.Kind()
targetNode := doc.Find(tagValue)
htmlValue := strings.TrimSpace(targetNode.Text())
switch kind {
case reflect.String:
// ...
case reflect.Int, reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64:
// ...
case reflect.Float32, reflect.Float64:
// ...
case reflect.Struct:
// ...
case reflect.Slice:
// ...
default:
fmt.Printf("unsupported kind [%s][%s]\n", kind, field.Name)
break
}
}
// ...
}
This process is straightforward, NumField() returns how many field the struct has, and Field() returns a StructField which contains information about a field such as name, type, and kind. And by the way, the difference between type and kind is kinda tricky to understand, I usually think it this way, if I define a struct named MyStruct then its type is MyStruct and its kind is struct.
Then, based on the field’s kind, I need to process the DOM node content differently. For example, if it’s int, I would do something like this
case reflect.Int, reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64:
if htmlValue == "" {
fieldPointer.SetInt(0)
break
}
intValue, err := strconv.ParseInt(htmlValue, 10, 64)
if err != nil {
fmt.Printf("unable to convert value to [%s][%s]\n", kind, field.Name)
fmt.Println(err)
break
}
fieldPointer.SetInt(intValue)
break
You might wonder, where the heck does fieldPointer come from, well, I omitted few parts in the for loop. Here is where they are defined
ps := reflect.ValueOf(structure).Elem() // <--- was omitted
for i := 0; i < elem.NumField(); i++ {
// ...
field := elem.Field(i)
// ...
fieldPointer := ps.FieldByName(field.Name) // <--- was omitted
if !fieldPointer.CanSet() {
continue
}
kind := field.Type.Kind()
// ...
I’m gonna have to step a few steps back to explain ValueOf() because it took me some time to understand it (and TypeOf) at first. In this example
type Person struct {
Title string
Age int
}
var person Person
field := reflect.TypeOf(&person).Elem().Field(0) // points to Title (the field)
value := reflect.ValueOf(&person).Elem().Field(0) // 0 (the value)
Field is the definition of a field in the struct, it contains meta data such as Name, Tag. It has nothing to do with the actual value inside the field. Value on the other hand, refers to the actual value that the field contains in its memory address. Without value, I won’t be able to set the data. Also, it needs to be “writable”, otherwise the code will panic
reflect.ValueOf(person).Field(0).CanSet() // false
reflect.ValueOf(&person).Elem().Field(0).CanSet() // true
The first call uses a struct, and since it’s just a value, I won’t be able to change its content. The second call uses a pointer to a struct (that’s why I have to do Elem() to get the struct that the pointer is pointing to). With a pointer, I’m now be able to set values.
Alright, with that out of the way, let’s continue with the parsing logic. All the primitive values are pretty much handled the same way, read value, convert it if need, and write it back. struct on the other hand requires a bit more work
case reflect.Struct:
// create a new struct pointer and recursively extract data from it
nestedStruct := reflect.New(fieldPointer.Type()).Interface()
recursivelyParseDoc(targetNode, nestedStruct)
fieldPointer.Set(reflect.ValueOf(nestedStruct).Elem())
break
Few things here, reflect.New(fieldPointer.Type()) returns a pointer to the nested struct. And because of how I use recursivelyParseDoc (passing a pointer), I need to call Interface() to convert the reflection Value to an actual struct pointer.
After I have got the value from the recursive call, I can just call Set() to update the value in the main struct. Because of how the struct is defined (value instead of pointer), I need to do an additional call to Elem() (Elem seems to be the MVP in most cases) to get the value that the pointer points to
As for slice, it’s mostly the same with few additional changes. Firstly, fieldPointer.Type().Elem() return the type of the slice’s elements. Then logic to create a new struct to be appended to the slice is similar to the normal struct case. Each struct/element created that way is then passed to recursivelyParseDoc. The final result is appended to the field (pointer) of the main struct (or the one level above struct of the nested struct contains another struct - struct-ception!) using reflect.Append(fieldPointer, reflect.ValueOf(nestedStruct).Elem()).
case reflect.Slice:
// first get the Type of the children
childType := fieldPointer.Type().Elem()
// then loop through each matched elements and populate the struct
targetNode.Each(func(i int, selection *goquery.Selection) {
nestedStruct := reflect.New(childType).Interface()
recursivelyParseDoc(selection, nestedStruct)
fieldPointer.Set(reflect.Append(fieldPointer, reflect.ValueOf(nestedStruct).Elem()))
})
One thing to remember here is that the whole process needs to be resolved around reflection and not actual data. Data need to be wrapped inside one of the reflection values before setting it.
And that’s it, I have my HTML parser which doesn’t depend on the actual implementation. This is achieved by using tags to separate the data structure from how the data is retrieved. However, this is just a naive implementation with lots of room for improvement. There are several obvious features that I should add such as
- Support DOM attributes, the current implementation just call
Text()to extract the data, and it’s common to get the data from the HTML tag attribute - Support more data types. I have not explored all of the primitive data types that Go provides yet, so I’m pretty sure that there are many types that I have missed
- Support slices of primitive types. For now when it’s a slice, the code assumes that it’s a slice of struct. In reality, it’s also common to extract data to a slice of string (for example to get a list of tags)
After this small exercise, I have learned a lot about golang’s reflection system. Reflection is one of my favourite features in any programming language, and it’s one of the many reasons that convinced me to give golang a try!
Updated 2020-07-09 here is the package https://gitlab.com/tanqhnguyen/gohtml I’m using it in my personal project but it’s not by any mean battle tested since my use case is just simple HTML parsing :)