Setting up a simple CI/CD flow with k3s and gitlab
Yeah, it’s a new year and it’s time for a new setup! I have been using docker swarm as my personal cluster for the past year. As I’m exposed to kubernetes more and more in my job, I just thought that maybe it’s time for me to actually do something with kubernetes in my free time to learn more about it. Besides, having knowledge about kubernetes benefits me in many ways considering how popular kubernetes has become.
In this blog post, I’m going to describe how I set up my personal cluster using k3s (a Lightweight kubernetes distribution) and rewrite the CI/CD pipeline to deploy to the new cluster instead of the old docker swarm cluster.
I’m assuming that you all have the basic knowledge of Kubernetes (pod, service, deployment, ingress etc…), and will not go into details when it comes to the k8s manifests
What is this k3s thing?⌗
As opposed to k8s, which is the first + last letters of kubernetes and 8 truncated characters in between, k3s doesn’t have any long form (or at least not that I’m aware of). K3s is capable of nearly everything k8s has to offer, meaning that you can write your manifests normally and it’s highly possible that you can apply them to either a full-fledged k8s cluster or a k3s cluster. The main reason why I chose k3s instead of the “standard” k8s distribution is because of the hardware constraints. According to the offical guide, a master node in a k8s cluster requires at least 2GB RAM, my tiny cloud instance in hetzner has exactly 2GB but I’m running other stuff there as well.
Another reason is the learning curve, it will probably take a lot more time for me to learn how to set up a proper k8s cluster compared to a 5-min 1 command run to set up a k3s cluster with everything I need to kickstart my journey with k8s (well technically not k8s but a k8s compliant cluster).
Set up a k3s cluster⌗
First thing first, we need to set up a k3s cluster. For the sake of simplicity, I’m gonna set up a simple 1 master node cluster. k3s is capable of having a multi master setup for high availability.
There are several ways to set up a k3s cluster, the most straightforward (and official) way is to run this command in your master node
curl -sfL https://get.k3s.io | sh -
and you are good to go. There are several environment variables that you set to configure the setup process, but the command itself by default should set up everything.
And to join a cluster, simply run this in your worker node
curl -sfL https://get.k3s.io | K3S_URL=https://myserver:6443 K3S_TOKEN=mynodetoken sh -
I shamelessly copied it from the official docs. The value used for K3S_TOKEN can be found from /var/lib/rancher/k3s/server/node-token in the master node.
Alternatively, you can also use k3sup to set up the cluster and your local kubectl at the same time. Just need to run this in your local machine
k3sup install --ip $IP --user root
This assumes that you have added your SSH key to the server. The user can be something other than root. There are other options as well, you can check them out here
After running this, you will also have access to kubectl, and then you can see what nodes are in the cluster. I have only 1 here because I don’t need to care about high availability for my setup (yet)

kubectl get nodes
NAME STATUS ROLES AGE VERSION
dev-1 Ready master 4d1h v1.19.5+k3s2
To join a cluster, run this
k3sup join --ip $AGENT_IP --server-ip $SERVER_IP --user $USER
Notice that you don’t even have to get the token, k3sup will do all of that for you.
Connect to the k3s cluster from the gitlab CI/CD pipeline⌗
Although Gitlab has a nice k8s integration (which can be used with any k3s clusters because they are compatible), we can do this in a generic way so that it can be applied to any other CI/CD platforms.
The main idea is to use kubectl to manage the cluster from within the CI/CD pipeline deployment step. In order to connect to the cluster, we need 2 things
- The Certificate Authority (CA) of the cluster so that our connections are secured by TLS
- A credential to with proper permissions to access the cluster
Let’s see how it works first and then we can go into details
kubectl config set-cluster k8s --server=https://$KUBE_HOST:6443 --certificate-authority=$KUBE_API_CERT
kubectl config set-credentials k8s-deployer --token=$KUBE_API_TOKEN
kubectl config set-context k8s --cluster k8s --user k8s-deployer
kubectl config use-context k8s
Pretty standard setup, first we need to define the cluster (its IP adddress and the CA used for TLS). Then, we need to set a credential (in form of a Bearer token) to connect to the cluster. After that, it’s just normal stuff to make sure we are running the correct context.
And I happen to have all the necessary commands to do get/create all the necessary data (make sure you are using the default namespace when running these commands)
SERVICE_ACCOUNT=blog-deployer
kubectl create serviceaccount $SERVICE_ACCOUNT
kubectl create clusterrolebinding $SERVICE_ACCOUNT --clusterrole cluster-admin --serviceaccount default:$SERVICE_ACCOUNT
KUBE_DEPLOY_SECRET_NAME=`kubectl get serviceaccount $SERVICE_ACCOUNT -o jsonpath='{.secrets[0].name}'`
KUBE_HOST=`kubectl get ep -o jsonpath='{.items[0].subsets[0].addresses[0].ip}'`
KUBE_API_TOKEN=`kubectl get secret $KUBE_DEPLOY_SECRET_NAME -o jsonpath='{.data.token}'|base64 --decode`
KUBE_API_CERT=`kubectl get secret $KUBE_DEPLOY_SECRET_NAME -o jsonpath='{.data.ca\.crt}'|base64 --decode`
There are several things here, first we need to create a service account and then we need to add (bind) that service account to the cluster-admin cluster role. The cluster-admin role is a bit too much because it has access to the entire cluster. But for the sake of simplicity I just use the most powerful one to avoid any permission problems during the process.

Then we need to get the secret name of the service account which contains all the necessary credentials to connect to the cluster using that service account, namely the (bearer) token and the certificate authority to secure the connection. With all that available, we can now set some environment variables in gitlab (Settings -> CI/CD -> Variables)
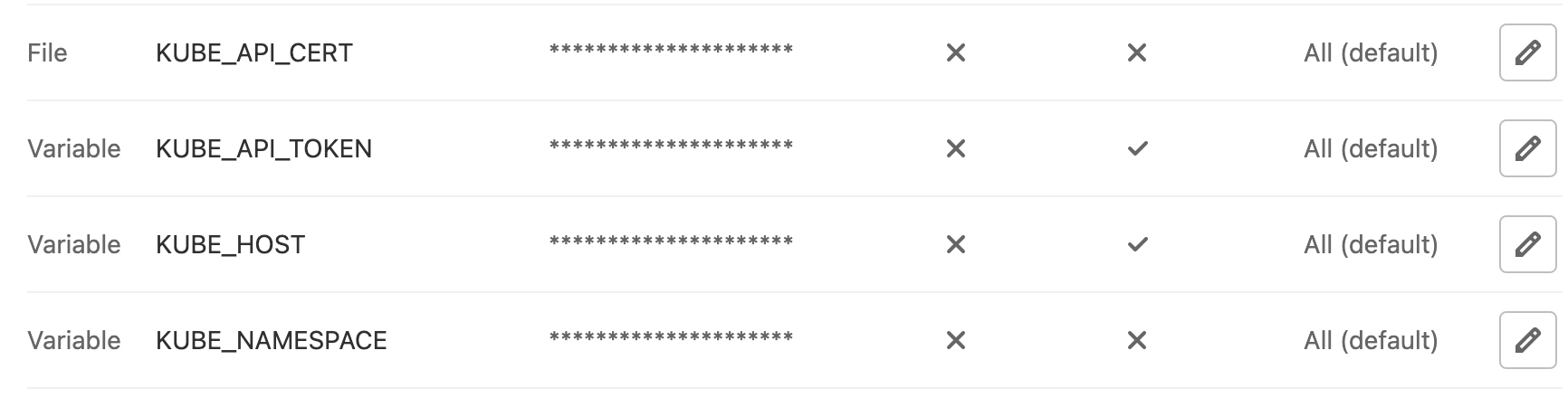
One tip here is to create the KUBE_API_CERT as a “file” variable which is a neat feature of Gitlab CI/CD (more details can be found here). Without it, we would have to do 2 steps
echo $KUBE_API_CERT > /tmp/ca.crt
kubectl config set-cluster k8s --server=https://$KUBE_HOST:6443 --certificate-authority=/tmp/ca.crt
and then we always need to clean it up (rm /tmp/ca.crt) after we are done. With the file variable in Gitlab, we can just use the environment variable.
Now that we have a working kubectl configuration, to actually do the deployment, the good old kubectl apply -f kubernetes works just fine (with some drawbacks).
Here is the manifests that I’m using to deploy this blog. It’s for krane but the overall structure is the same as regular manifests. We will go into details why simly doing kubectl apply -f is not enough.
And here is a simple CI/CD pipeline that builds the docker image, and then publishes it to my k3s cluster.
Why is kubectl apply not enough?⌗
Unlike docker swarm’s compose files where you can at least refer to environment variables, the standard k8s manifests are just static files (as far as I know). You can’t for example change your image tag to refer to the latest deployment tag, what you can do is to always use latest which is not a good thing because you can’t roll back (what does previous latest even mean). For example here is the deployment manifest written normally.
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: blog-site
labels:
app: blog-app
spec:
replicas: 2
selector:
matchLabels:
app: blog-app
template:
metadata:
labels:
app: blog-app
spec:
containers:
- name: blog
image: registry.gitlab.com/tanqhnguyen/blog:latest
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "96Mi"
cpu: "500m"
ports:
- containerPort: 80
With this deployment, the best we can do is to deploy the latest image. And if there are some problems with the latest image, we can’t roll back (which is fine for my blog but not really for a real production environment). There are 3 solutions (that I know of at the moment) to solve this particular problem.
- Use
sedto replace the fixedlatesttag with the actual latest image tag (in Gitlab, it’s$CI_COMMIT_SHORT_SHAvariable) before callingkubectl apply - Use helm and add the manifests into a helm chart with proper variables. Then we can use helm to install the package with custom values when installing/updating the chart
- Use krane and change the manifest to be an ERB template. Then we can use krane to render the manifest templates and provide custom bindings
All solutions have their pros/cons, I won’t go into details because it’s outside the scope of this blog post. After evaluating these options, I decided to go with (3) because in addition to the manifest template, krane also has better support for managing secrets (via EJSON) among other things.
Now with krane we can change this line to make it possible to deploy using the commit hash as image tag instead of latest
image: <%= registry_image %>:<%= commit_short_sha %>
And instead of running kubectl apply -f, we need to render the templates first and then pipe the output to kubectl apply
krane render -f kubernetes --bindings=registry_image=$CI_REGISTRY_IMAGE,commit_short_sha=$CI_COMMIT_SHORT_SHA | krane deploy ${KUBE_NAMESPACE} k8s -f -
And that’s it, it’s my first time setting up a k3s cluster and expose myself more to k8s workflow so there might be some weird stuff here and there. You can also check out the real setup in my gitlab repository