Get data from a youtube gaming page
In my current project, I need to grab data from youtube gaming pages. I have done similar thing previously, but with the normal youtube channel pages. The new gaming pages are rendered in a completely different way. It took me some digging around the source code to finally be able to figure out a way to extract data. This blog post summarizes what I have done to get the data out of a youtube gaming channel page.
Youtube gaming⌗
Youtube gaming is a new service from youtube aiming directly at gamers by providing easy access to gaming videos. What I want to do is to get data from a gaming channel for further analysis. For example, Markiplier. From his channel, we can know which games he has made videos about or how many views he has for the past 3 months. There are a lot of things I can do with Youtube gaming, but for the purpose of this post, I will focus on getting the games associated with the videos of a youtube channel. However, this is not 100% accurate because of the game matching agorithm used by Youtube to automatically detect game based on the video data. I will simply get what youtube shows. Some of you might ask why don’t I use the Youtube Data API? Using the API comes with a quota limit, although it’s high enough for me to not worry about it for now. But having a second option that doesn’t touch the API is always better in term of resource management.
First attempt⌗
As usual, the first thing comes to my mind when I want to get something from a web page is to open its source code and look for the data using CSS selectors. However, youtube gaming is different, it doesn’t render the page in the server-side. Instead, it pushes the rendering job to the client side, which is the web browser. And it’s usually done by some Javascript magic (Angular I guess, I don’t know for sure). Below is the piece of HTML code I find when opening a Youtube gaming channel page. It doesn’t have what I am looking for.
<link itemprop="url" href="https://gaming.youtube.com/user/markiplierGAME">
<meta itemprop="name" content="Markiplier - YouTube Gaming">
<meta itemprop="description" content="Welcome to Markiplier! Here you'll find some hilarious gaming videos, original comedy sketches, animated parodies, and other bits of entertainment! If this s...">
<meta itemprop="unlisted" content="False">
<link itemprop="thumbnailUrl" href="https://yt3.ggpht.com/-aSj-EnOjUkc/AAAAAAAAAAI/AAAAAAAAAAA/lQiWTDY9Sd0/s200-c-k-no-mo-rj-c0xffffff/photo.jpg">
<span itemprop="thumbnail" itemscope itemtype="http://schema.org/ImageObject">
<link itemprop="url" href="https://yt3.ggpht.com/-aSj-EnOjUkc/AAAAAAAAAAI/AAAAAAAAAAA/lQiWTDY9Sd0/s200-c-k-no-mo-rj-c0xffffff/photo.jpg">
<meta itemprop="width" content="200">
<meta itemprop="height" content="200">
</span>
Second attempt⌗
Another way that web applications usually do in order to fetch their data is to use AJAX requests. It might be the case for Youtube gaming. Let’s check the Network tab while opening the page.
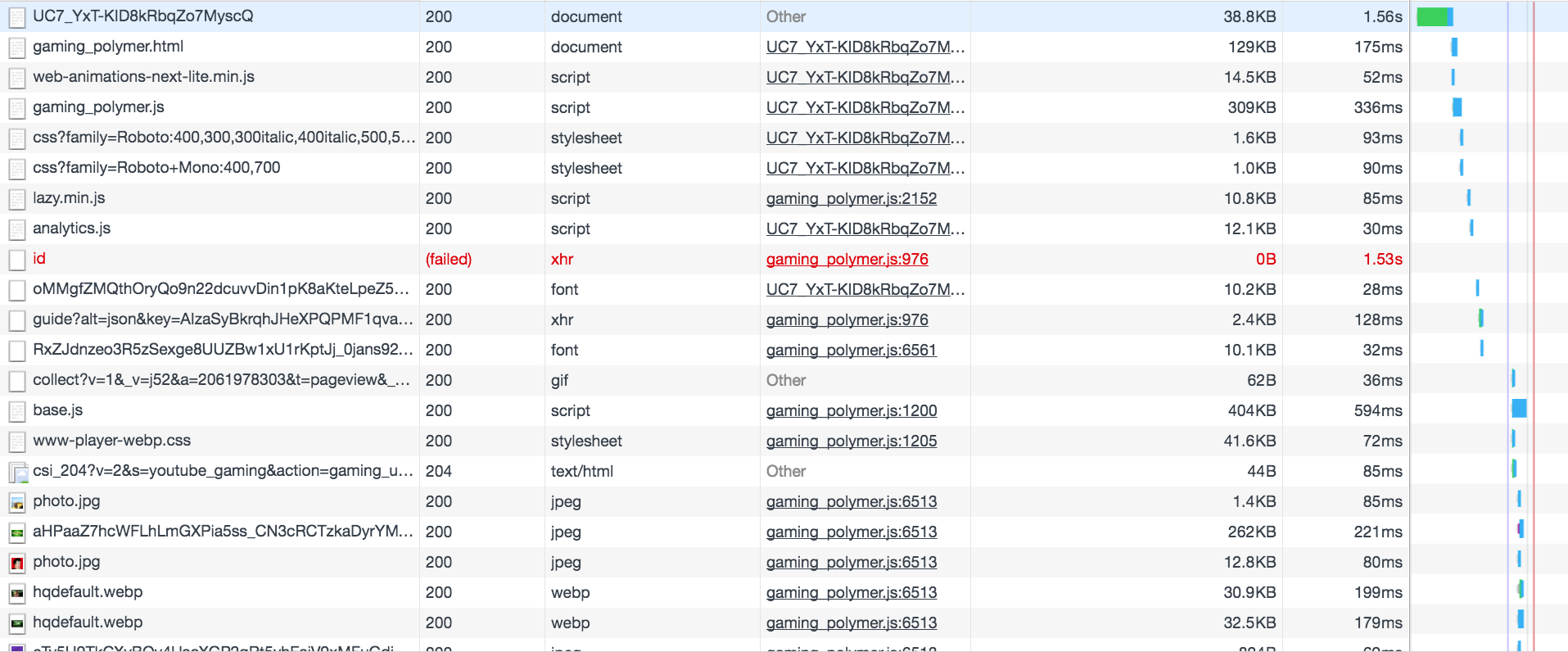
There is nothing useful among the inital requests. They are all for loading static assets, images, fonts and css files. There are some AJAX requests but for different services. So, relying on AJAX requests is also a dead end.
Third attempt⌗
If a page is not loading its data through AJAX requests and it doesn’t render any data initally, there is another way for it to get the data from the server-side which is to use the embedded data (prepared by the server-side) in the inital payload, which is the HTML page in this case. It’s usually in the form of server-side generated script tags. With that guess, I open the source code of the page again and it’s there, the data is embedded in a script tag along with about 10 other script tags in body.

Since the data is inside a script tag, the obvious solution is to execute it by eval and get the result (one can also use regular expression to extract the data but it is insanely hard to do that, and I am not that good with regular expression). Since I am running this in nodejs, it’s better to use V8 Virtual Machine. They (eval and vm) are doing the same thing but by using VM, I can also cache the compiled code and run it later to improve the performance.
First thing first, I need to get the content of the script tag containing the payload for rendering the UI. There are 2 ways:
- Use some HTML parsing library, for example cheerio, to parse the page the select the script tag and extract its content
- Use regular expression to extract the content of script tags
I am going to use regular expression because it’s simpler. I am not sure if it’s faster than parsing the whole HTML file or not. It might be slower because of the small amount of HTML Youtube gaming returns.
Either way, I still need to do extra work to select the correct script tag among all the script tags in the page. They don’t have any id or anything that can be used to as their unique identity, the only solution I could come up with is to check for a certain string to know which script tag to use.
const _ = require('lodash'),
request = require('request-promise');
const DEFAULT_HEADERS = {
// Be a Chrome
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.111 Safari/537.36',
// Use English
'Accept-Language': 'en-GB,en-US;q=0.8,en;q=0.7',
};
function fetchHtml(options) {
if (_.isString(options)) {
options = {
url: options
};
}
options.headers = Object.assign(options.headers || {}, DEFAULT_HEADERS);
return request(options);
}
const SCRIPT_TAG = /<script>(.*?)<\/script>/gi;
function getGamesOfChannel(id) {
return fetchHtml(
`https://gaming.youtube.com/channel/${id}`
).then(function (html) {
let matches = [];
let match = null;
html = html.replace(/\s\s+/g, ' ');
while ((match = SCRIPT_TAG.exec(html)) !== null) {
matches.push(match[1]);
}
matches = matches.filter((match) => {
// only get the one having setEmbeddedData inside
return match.indexOf('setEmbeddedData') !== -1;
});
if (!matches.length) return [];
const scriptContent = matches[0];
});
}
Note that I need to send the request as Chrome because Youtube uses that to reject requests coming from bots. The language is also set to English because Youtube uses the IP address of the request to determine the language for the page. The logic to select the correct script tag is simple, first use SCRIPT_TAG and a while loop to get all script tags in the page. Then simply pick the one having setEmbeddedData inside it. What is setEmbeddedData? It is a function used by Youtube gaming to set the data for rendering its UI, I can simply use that to extract the data.
Now that I have the correct script content that I need to run in order to get the data. It’s time to use V8 Virtual Machine (vm) to execute the code. One thing to notice here is that vm will execute the code as is, malicious code will also get executed, don’t use it to execute untrusted code. Since we are dealing with Youtube here, I trust them (for now at least).
const vm = require('vm');
function getGamesOfChannel(id) {
return fetchHtml(
`https://gaming.youtube.com/channel/${id}`
).then(function (html) {
let matches = [];
let match = null;
html = html.replace(/\s\s+/g, ' ');
while ((match = SCRIPT_TAG.exec(html)) !== null) {
matches.push(match[1]);
}
matches = matches.filter((match) => {
// only get the one having setEmbeddedData inside
return match.indexOf('setEmbeddedData') !== -1;
});
if (!matches.length) return [];
const scriptContent = matches[0];
const script = new vm.Script(scriptContent);
const fakeBrowser = {
window: {
ytg: {}
},
document: {
querySelector: function() {
return {
addEventListener: function() {}
}
}
},
ytg: {
core: {
DI: {
instantiate: function() {
return {
setEmbeddedInnerTubeData: (data) => {
// this refers to ytg.core.DI
this.data = data;
}
}
}
}
}
}
};
script.runInNewContext(fakeBrowser);
});
}
Let’s go through it. First I need to create a script instance using vm.Script class. Then I need to prepare a context for the script to run in. Below is the content of the script tag containing what I need
var setEmbeddedData = function() {
var cacheData = [];
cacheData.push({/* some data */});
cacheData.push({/* some data */});
cacheData.push({/* some data */});
ytg.core.DI.instantiate('ytg.net.NetworkManager').setEmbeddedInnerTubeData(cacheData);
}
if (window.ytg && ytg.core && ytg.core.DI) {
setEmbeddedData();
} else {
var script = document.querySelector(
'script[name="gaming_polymer/gaming_polymer"]');
script.addEventListener('load', setEmbeddedData);
}
Based on that, the context will have the following structure
{
window: {
ytg: {}
},
document: {
querySelector: function() {
return {
addEventListener: function() {}
}
}
},
ytg: {
core: {
DI: {
instantiate: function() {
return {
setEmbeddedInnerTubeData: (data) => {
// this refers to ytg.core.DI
this.data = data;
}
}
}
}
}
}
};
There are 2 definitions of ytg. The first one is to make window.ytg condition to be true in the if-else condition. The second one is also for the if-else condition, but it has some extra methods to hook into ytg.core.DI.instantiate('ytg.net.NetworkManager').setEmbeddedInnerTubeData(cacheData); for getting the cachedData because setEmbeddedInnerTubeData is called when setEmbeddedData is called. The final data can be accessed via fakeBrowser.ytg.core.DI.data. Next I need to extract the data from fakeBrowser.ytg.core.DI.data. It’s just a matter of looking into the JSON object and know which one to get, nothing hard in particular.
const tabs = _.get(
_.find(fakeBrowser.ytg.core.DI.data, {
path: '/browse'
})
, 'data.contents.singleColumnBrowseResultsRenderer.tabs', []);
const uploads = _.get(
_.find(tabs, (tab) => {
return _.get(tab, 'softTabRenderer.title') === 'UPLOADS';
})
, 'softTabRenderer.content.sectionListRenderer.contents[0].itemSectionRenderer.contents[0].gridRenderer.items', []);
return _.chain(uploads).map((upload) => {
return _.get(upload, 'gamingVideoRenderer.associatedGame.gameDetailsRenderer.title.runs[0].text', null);
}).compact().uniq().value();
And that results in an array of game titles associated with a channel.
But wait, it’s not everything. I have only processed the initial payload so far. When I scroll down, Youtube does some extra AJAX requests to fetch more data (it makes sense that they don’t try to load everything at once). And those AJAX requests require some security tokens which are also embedded in the initial payload. Getting all the videos is just a matter of making AJAX requests with suitable params and process the JSON responses. Therefore, I won’t cover it in this post.