So… I build my first gitops flow - Part 1
Not so long ago, I had a chance to get my hands dirty with improving the deployment flow of a project. Gitops was mentioned pretty regularly when I did my research. The more I read about it, the more I like the idea because I was always complaining why do I have to wait for the CI to build when I just change some random YAML file to update my deployment, it is a huge waste of time. In this series, I am going to write down the process from almost zero knowledge about gitops to having a functional gitops flow for a small team of around 40 engineers with 10+ services. The first part is mostly about finding and evaluating different solutions.
Background⌗
A bit of background about the project, we were using krane, so basically render the manifests (from erb files), and then do kubectl apply -f with a bunch of nice to have features like ejson support and separate phase to run individual Pod (for migration purposes). The flow is your typical push-deploy flow. Whenever we merge something to master, it triggers a CI flow to run all the tests, build a new image and then a CD flow is executed right after that to push all the manifests to our kubernetes cluster using krane.
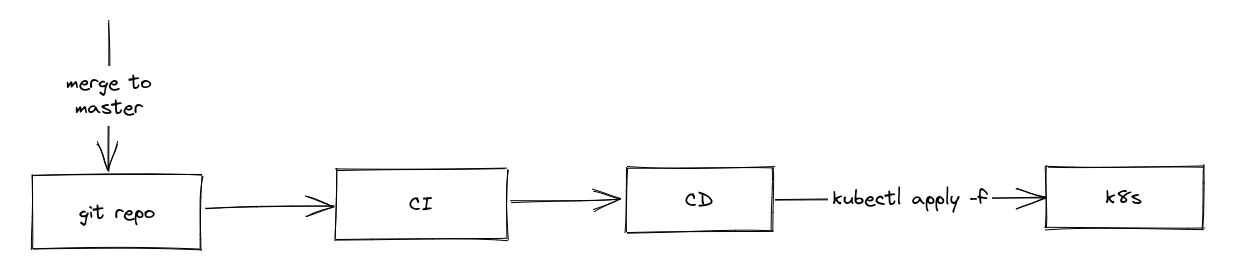
This had been working well so far, until one day when I needed to find the correct datadog annotations so that I can properly track my services. It was a horrible experience, every time I made a single tiny change to the deployment manifest, I needed to wait for the whole CI to finish before I can even deploy (I can of course do manual deployment but I want to avoid that). It was so frustrated that I started to notice all kind of problems with the current flow, for example
- When we want to revert something, the CI usually gets in the way. And if it’s urgent, whoever is responsible needs to know how to do a manual deployment, and we need to tell everyone to stop merging until the rollback is done with.
- I wanted to give canary deployment a go but with the current setup, it’s almost impossible to develop because of… the CI again.
With those 2 pain points, I decided to take the initiative to figure out a solution. Our organization doesn’t have a dedicated DevOps role, we developers all know a bit about Ops (as it should be with the DevOps principles), and anyone can step up to improve our setup. I just happened to be the one with the most free time at the moment.
Goals⌗
There are some constraints for the first iteration, though.
- I need to maintain the same flow as before, meaning that a deployment is automatically triggered whenever you merge to
master. - The setup should support one environment per cluster. For example production and staging environment.
- The setup should be simple enough for all other developers to adapt to their own services with minimal changes to the existing YAML files.
Gitops⌗
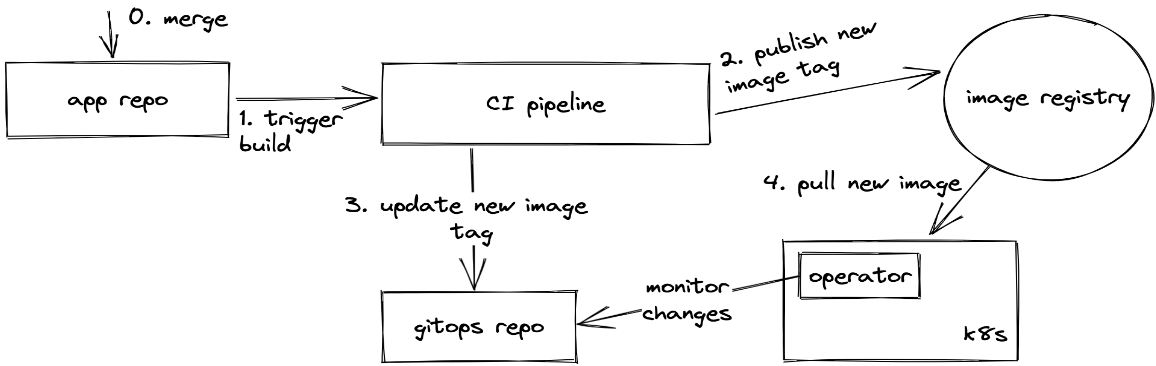
When doing my research about devops, I came across the term gitops, and after reading more about it, it actually addresses all of my problems. The core idea of gitops is to treat the git repo as the source of truth for everything (even infrastructure). It means that if in your repo, you are saying that the production version is v1, the production cluster will eventually be set to v1. The emphasis is on eventually because one of the components of a gitops flow is a kubernetes controller which monitors the current state (in the cluster) and the desired state (in the git repo). If they are different, the controller will trigger a sync to deploy the desired state (version).
Why is it important to have git as the source of truth? With the krane deployment flow, the application version is injected by the CD script, it means that whatever we see in the repo is just a placeholder, we need to actually check the cluster to see what’s being deployed there. Doing manual deployment is a dangerous process because one needs to have access to the production cluster locally (I try to avoid having any production credentials in my laptop). This principle also makes rollback a lot easier as we can just revert the latest commit that changes the version, and everything will be deployed within seconds.

Now that gitops is definitely the way to go, I need to choose a CD tool, at the time of writting, there are 2 most popular choices: ArgoCD and fluxCD. Both are CNCF graduated project, so in term of basic features, they are basically equal. But I decided to go with argocd instead of flux because argocd is a lot easier to install (just my personal opinion) and operate than flux. It even has a nice UI to click around instead of a purely CLI tool.
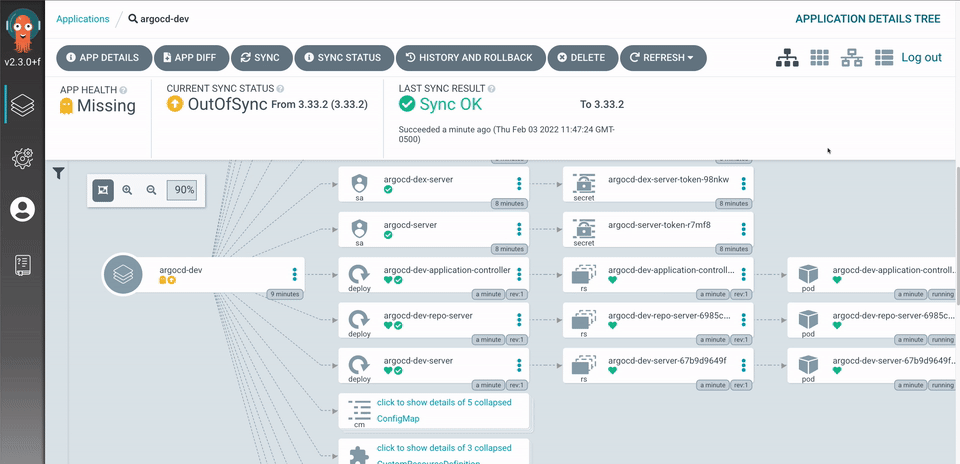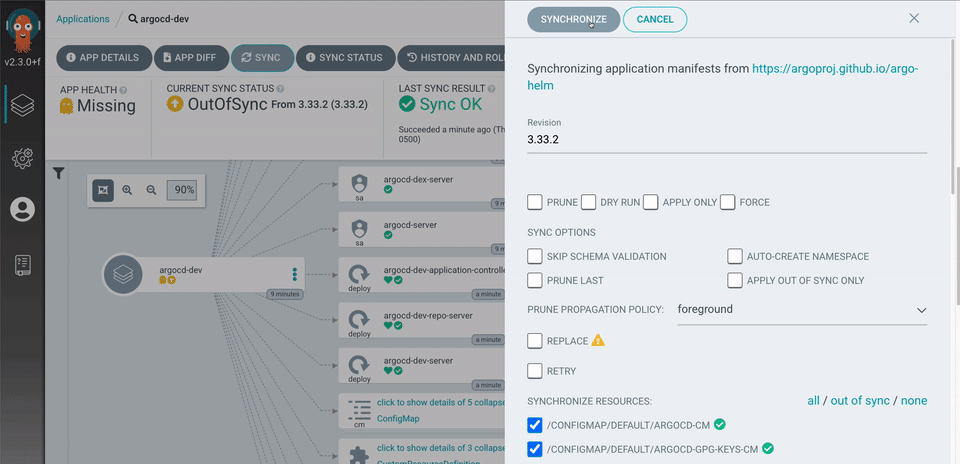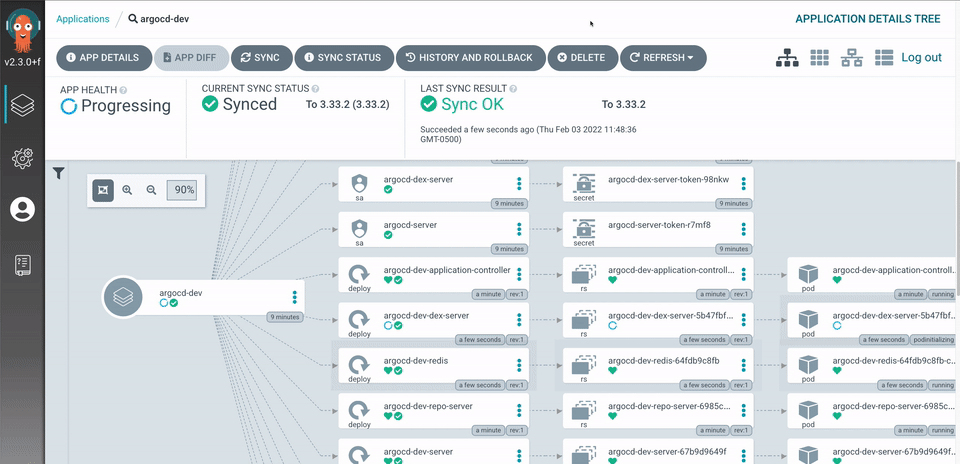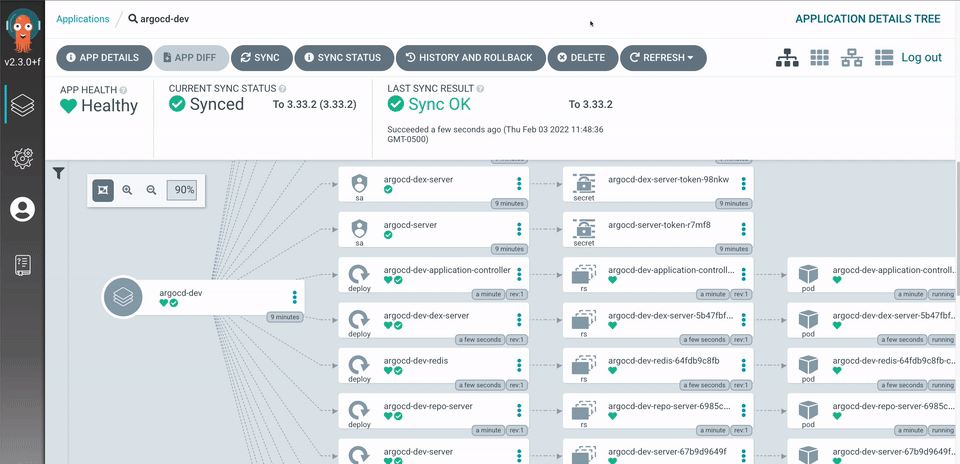
Before diving into the actual migration process, I have several decisions to make regarding the overall setup.
Where to put the k8s manifests?⌗
Traditionally, I have seen a lot of projects just store the k8s manifests inside the repo. It’s fine for most cases, but if you have a lot of repos, the amount of copy/paste between repos is going to be insane, if not impossible to manage. This is one big change the I need to convince the rest of the engineering team.
Centralizing all the k8s manifests in one place (we call this repo gitops, big surprise!!!) makes it a lot easier to share YAML (Don’t Repeat your YAML), and different teams can easily learn from each other. And it makes maintenance a lot a lot easier as one won’t have to constantly jumping around different repos. This setup has its own share of problems, for example access policy can’t be easily controlled within a single repo, one can see everything in the repo if they have access to the repo. This is not a problem for us because we all trust our engineers to do the right things, but it might be a problem for some big corporations that have strict access control policies.
How to organize ArgoCD operator?⌗
The next question is where to put the operator? I briefly mentioned the operator few paragraphs ago. To recap, an operator (lives inside a k8s cluster) is responsible for monitoring the changes (in the repo), and reconcile whenever needed. Here I have 2 options (without involving a 3rd party control plane), either put the ArgoCD instance inside the target cluster or have a centralized ArgoCD instance and deploy to multiple clusters from there (hub and spoke).
Having standalone instances is better in our case because it makes the infrastructure as code (IaC) more consistent as we can define how to set up the ArgoCD instances (for each environment) in a similar manner to the rest of the infrastructure setup. It also eliminates single point of failure because each cluster is independently managed by a separate ArgoCD instance (or a group of ArgoCD instances in case of high availability setup).
Secret management⌗
The next problem that I need to tackle is how to manage secrets. With krane, we have ejson support to store the encrypted secrets directly in the repo. This is a security concern but it is very easy to start with in small projects/teams. With argocd, however, ejson is not even a thing because argocd doesn’t care how the repo manages its secrets. Therefore, I must find an alternative way to manage secrets.
After doing some researches on the topic, there are many options but they all boil down to 2 approaches, either store the secrets as encrypted in the repo or use a centralized secret store (Vault for example). For storing secrets in the repo, I was evaluating SealedSecret. The idea is quite similar to EJSON, except that we don’t have to manually create the secrets to encrypt/decrypt EJSON files. Instead the encrypt/decrypt process is tied to the controller installed inside a namespace. In other words, if you encrypt a secret in one namespace, it can only be decrypted in the same namespace. This is a deal breaker for us because we want to eliminate the need to have k8s access from local (The plan is to introduce a web-based developer portal to interact with k8s clusters). In addition to that, this process can’t be easily managed by our IaC solution (pulumi at the time), or maybe I just don’t know how to do it.
The other option is to use a centralized secret manager. Fortunately, we use GCP and they have a nice and easy to use secret manager. It’s also supported by pulumi. The process is simple, secrets are encrypted and stored in the IaC repo (which will be merged with the gitops repo at some point in the future) managed by pulumi, and then created in the GCP secret managers in the correct project (we have different projects for production and staging).
With all the secrets have been taken care of, the natural next step is to figure out how to get the secrets from the secret manager into the k8s namespace and create proper Secret resources. For this, we use external-secrets because of its simplicity and straightforward setup / usage (that even I can set up everything correctly in the first try). The steps are simple
- Set up a GCP secret manager provide
- Create an
ExternalSecretresource - Profits!!!
How to manage those nasty YAML files?⌗
I know that we all love and adore YAML files but if you have to manage hundreds of them, you will start hating YAML (at least I do). This is one of the easiest part, ArgoCD supports (at the time of writing) kustomize, helm and jsonnet, so to make my life easier, I just need to pick one of them.

For our case, the winner is obvious, it’s kustomize because
- It’s just YAML on steroid, we can simply copy/paste our old manifests and make few changes here and there.
- It’s built into kubectl since 1.14.
- Its patching engine makes everything explicit and obvious.
Version management⌗
And finally, last but not least, there is a problem of how to manage the app version in a gitops flow. One of the core principles of gitops is that the repo is the source of truth, meaning that if you see the app version in the repo, it must be the version in the production cluster or something is horribly wrong.
With krane, we use erb and when we render the templates, we simply pass the new commit hash (which happens to be the docker image version) to the deployment manifest so that it can deploy new pods using the new docker image. With argocd, we don’t have that luxury, everything must be explicit, even the docker image version. There are again many options here, I evaluate and narrow them down into 2 prime candidates.
First option is to use the built-in images transformer to replace the image placeholder with a correct value. I’m using this approach for deploying my blog.
// kustomization.yaml
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
resources:
- deployment.yml
- ingress.yml
- service.yml
- cert.yml
namespace: blog
images:
- name: blog
newName: registry.gitlab.com/tanqhnguyen/blog
newTag: 54dc960b // <-- this is the actual version
// deployment.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: blog-site
labels:
app: blog-app
spec:
replicas: 2
selector:
matchLabels:
app: blog-app
template:
metadata:
labels:
app: blog-app
spec:
containers:
- name: blog
image: blog // <--- and this is a placeholder
resources:
requests:
memory: "32Mi"
cpu: "250m"
limits:
memory: "64Mi"
cpu: "500m"
ports:
- containerPort: 80
And when I have a new version, I just need to run this command to update the version, and then commit the change.
kustomize edit set image blog=$CI_REGISTRY_IMAGE:$CI_COMMIT_SHORT_SHA
This approach has a limitation that by default you can only update the image field. For simple stuff (like my blog), it works without any problem. However, for our actual production setup, we need to have some extra annotations for datadog to know the current version, and we also want to set the current version as a env variable so that our app can pick it up.
Next option is to use a combination of ConfigMapGenerator and replacements. The basic idea here is to generate a ConfigMap from a file (which happens to contain the app version), and then define a replacement transformer to “copy” the value from the generated ConfigMap over to specific fields.
Let’s start with a file
# version.properties
VERSION=54dc960b
then add a ConfigMapGenerator
// kustomization.yaml
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
resources:
- deployment.yml
- ingress.yml
- service.yml
- cert.yml
namespace: blog
configMapGenerator:
- name: version-cm
envs:
- version.properties
This will generate a ConfigMap called version-cm-<hashed-value>, every time the file content changes, a new config map will be generated. But we can refer to version-cm and kustomize will know to use the actual value.
The final piece of the puzzle is the replacement transformer
// set-version.yaml
- source:
kind: ConfigMap
name: version-cm
fieldPath: data.VERSION
targets:
- select:
kind: Deployment
name: blog-site
fieldPaths:
- spec.template.spec.containers.[name=blog].image
options:
delimiter: ':'
index: 1 // <-- note that I have to set the index here to 1 to set just the image tag
// kustomization.yaml
replacements:
- path: ./set-version.yaml
// deployment.yaml
spec:
containers:
- name: blog
image: registry.gitlab.com/tanqhnguyen/blog:placeholder // <-- need to change this to refer to the registry URL
You can imagine that with version-cm as a ConfigMap, we can easily set env variables for our app, or simply have another replacement transformer to set whatever field we want. And when there is a new version, we can simply update the version.properties file with the latest version.
And with that, I now have a “good enough” setup to start migrating old manifests over one server at a time. In the next blog post, I am going to describe how I set up argocd to manage itself and automatically discover and manage new apps.